Yuxuan Wang (王雨轩)I am currently an undergraduate student at the School of Computer Science and Technology at Beijing Institute of Technology. I am also an intern at Mμ Lab at the Institute of Artificial Intelligence, Peking University, where I focus on model architecture under the guidance of Professor Muhan Zhang. I will begin my master's studies at the School of Software and Microelectronics at Peking University in September 2026, under the supervision of Professor Muhan Zhang and Professor Zhonghai Wu. |

|
News |
|
PapersMy research interest focuses on foundation models. I am dedicated to model compression, model acceleration, and related areas. |
|
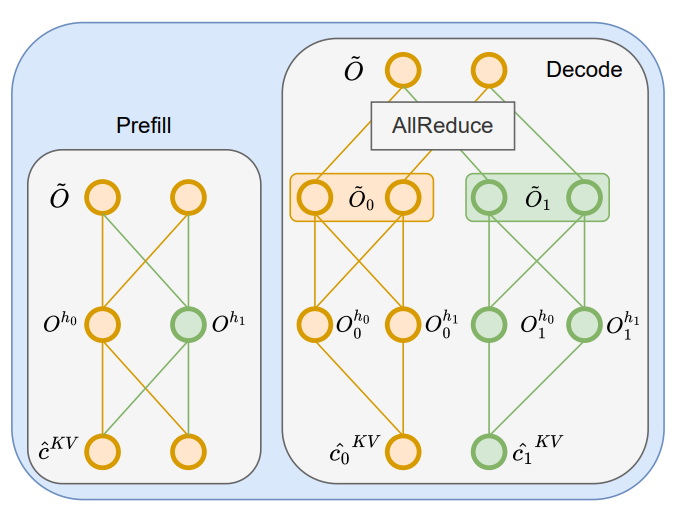
TPLA: Tensor Parallel Latent Attention for Efficient Disaggregated Prefill and Decode InferenceXiaojuan Tang, Fanxu Meng, Pingzhi Tang, Yuxuan Wang, Di Yin, Xing Sun, Muhan Zhang arxiv preprint, 2025 arxiv / We propose Tensor-Parallel Latent Attention (TPLA): a scheme that partitions both the latent representation and each head’s input dimension across devices, performs attention independently per shard, and then combines results with an all-reduce. TPLA preserves the benefits of a compressed KV cache while unlocking TP efficiency. |
|
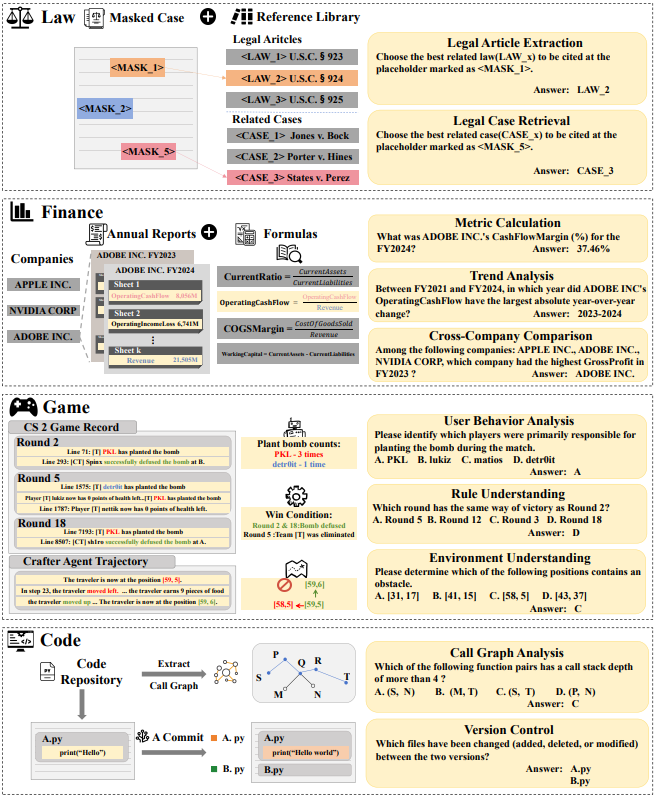
LooGLE v2: Are LLMs Ready for Real World Long Dependency Challenges?Ziyuan He*, Yuxuan Wang*, Jiaqi Li*, Kexin Liang, Muhan Zhang NeurIPS Datasets and Benchmarks Track, 2025 arxiv / code / huggingface / LooGLE v2 is a benchmark designed to evaluate the long-context and long-dependency capabilities of large language models. Its key highlight is the use of ultra-long texts, with a strong emphasis on long-dependency, and it is entirely designed with real-world, real-task scenarios. |